Stability AI’s new image generation model: Stable Cascade
Stability AI's new image-generating AI model, Stable Cascade, promises faster and more powerful photo generation. With features like inpainting, outpainting, and canny edge, it's a game-changer in the AI media

Stability AI has recently unveiled its latest image generation model, Stable Cascade, which is expected to outperform its predecessor, Stable Diffusion, in terms of speed and power. This new model offers a range of features, including the ability to generate photos and provide variations of the original image, as well as enhance the resolution of existing pictures. Additionally, it includes text-to-image editing capabilities such as inpainting, outpainting, and canny edge, allowing users to manipulate specific parts of an image and create new photos based on existing ones.

This new model is currently available on GitHub for researchers, although it is not yet approved for commercial use. Despite the release of image generation models by tech giants like Google and Apple, Stability AI’s Stable Cascade offers a unique set of features and capabilities.
Unlike Stability’s flagship Stable Diffusion models, Stable Cascade is not a single large language model. Instead, it consists of three distinct models that utilize the Würstchen architecture. The initial stage, stage C, compresses text prompts into latents, which are then decoded by stages A and B to fulfill the request.
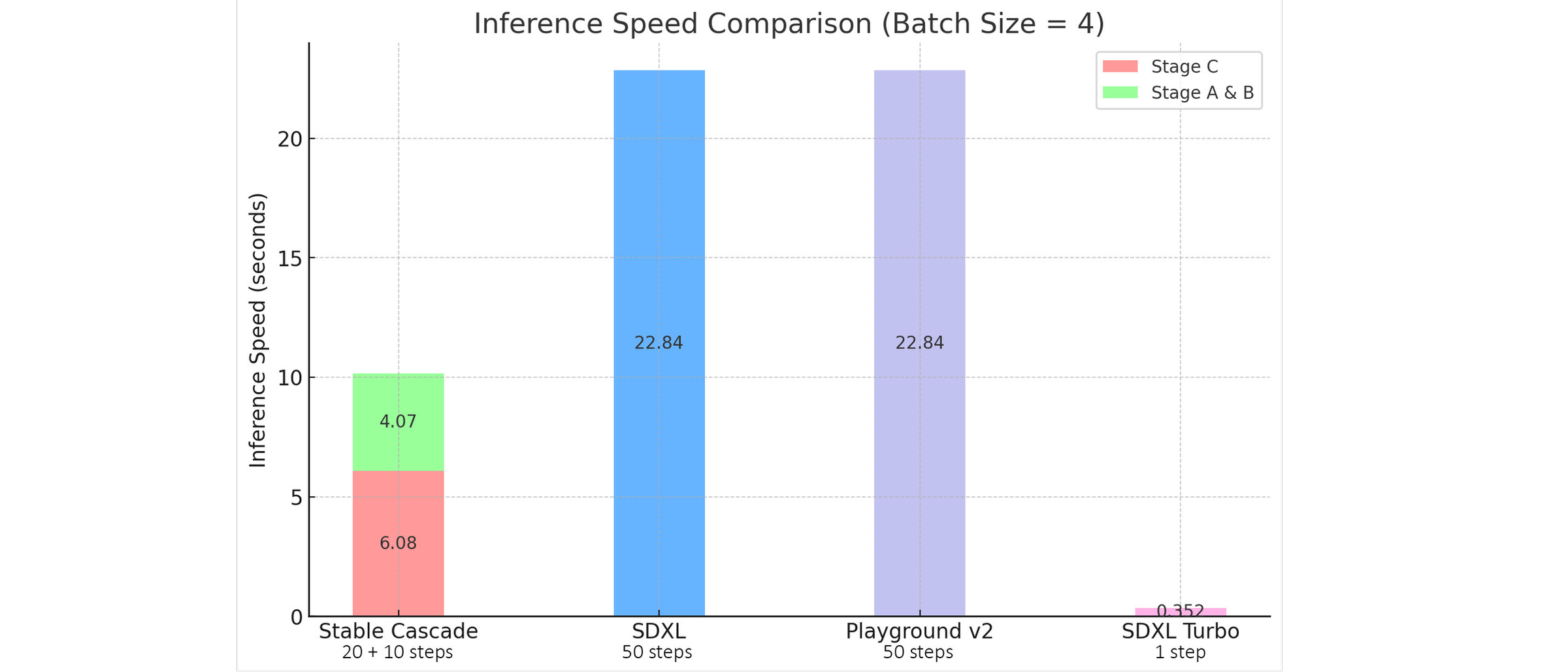
By breaking down requests into smaller components, the model reduces the memory required and runs faster, resulting in improved prompt alignment and aesthetic quality. In fact, it takes only about 10 seconds to create an image, compared to the 22 seconds required by the current SDXL model.